GLM-5.2 — the open agentic-frontier play
Charts
GLM-5.2 — the open agentic-frontier play
An eval-founder read of zai-org/GLM-5.2 (Zhipu / GLM team, MIT, released 2026-06-16; tech report arXiv:2602.15763, "GLM-5: from Vibe Coding to Agentic Engineering"). Numbers are the card's own self-reported table. onlylabs signal.
0. What this is
- *An open (MIT) flagship built for long-horizon agentic engineering — the thesis is literally the tech-report title, "from Vibe Coding to Agentic Engineering." It ships a solid 1M-token context* and "advanced coding with flexible effort" (multiple thinking-effort levels).
- Rare transparency: it publishes a full cross-vendor comparison table — vs GLM-5.1, Qwen3.7-Max, MiniMax M3, DeepSeek-V4-Pro, Claude Opus 4.8, GPT-5.5, Gemini 3.1 Pro. Most frontier cards don't (the GPT-5.6 system card, for contrast, has zero competitor columns).
- Architecture: IndexShare reuses one indexer across every four sparse-attention layers (2.9× fewer per-token FLOPs at 1M context); an improved MTP layer lifts speculative-decoding acceptance length up to 20%.
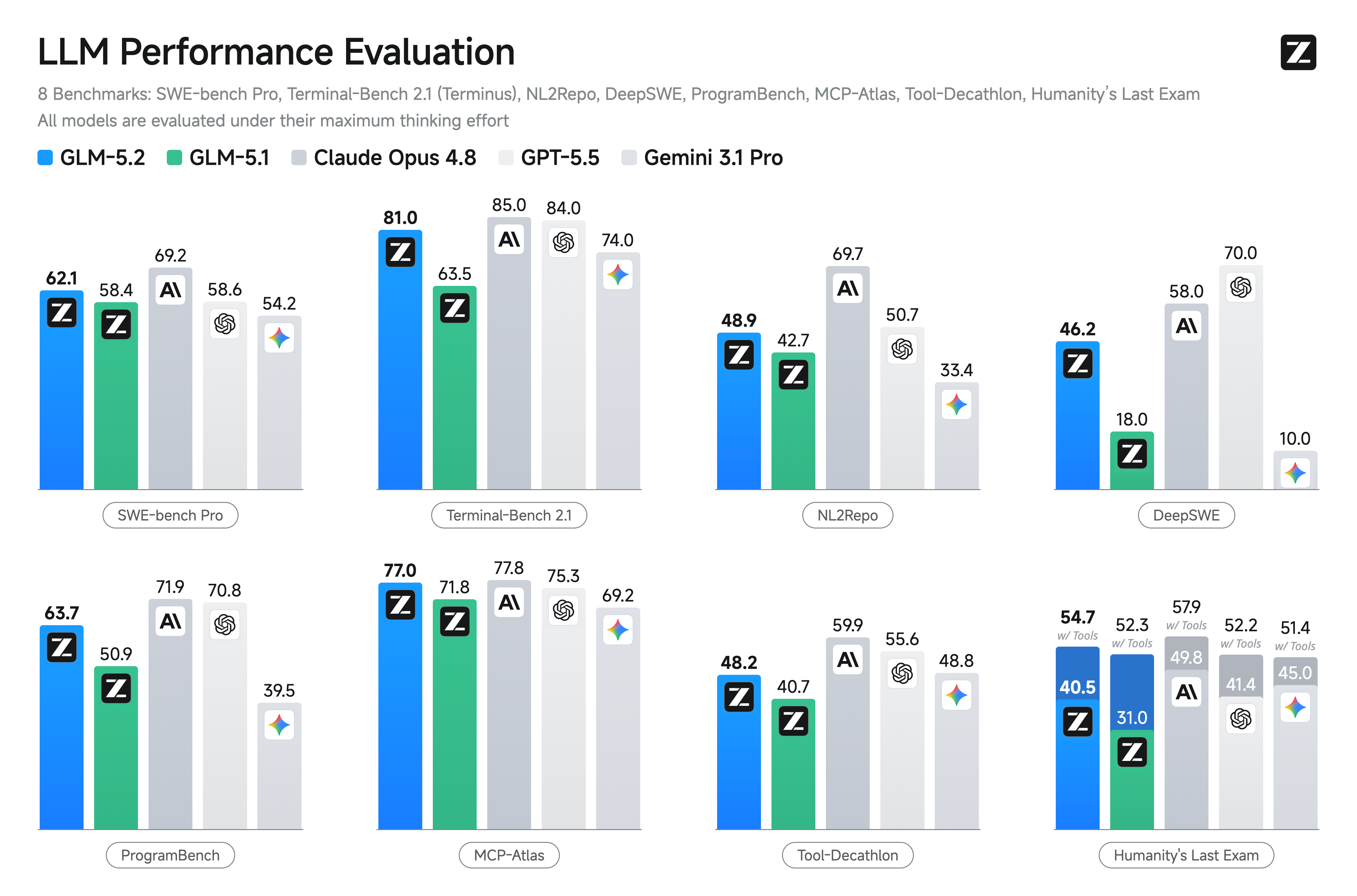
1. The benchmark profile (self-reported, cross-vendor)
| Benchmark | GLM-5.2 | GLM-5.1 | DeepSeek-V4-Pro | Claude Opus 4.8 | GPT-5.5 | Gemini 3.1 Pro |
|---|---|---|---|---|---|---|
| Reasoning | ||||||
| HLE | 40.5 | 31 | 37.7 | 49.8* | 41.4* | 45 |
| HLE (w/ tools) | 54.7 | 52.3 | 48.2 | 57.9* | 52.2* | 51.4* |
| AIME 2026 | 99.2 | 95.3 | 94.6 | 95.7 | 98.3 | 98.2 |
| GPQA-Diamond | 91.2 | 86.2 | 90.1 | 93.6 | 93.6 | 94.3 |
| IMOAnswerBench | 91.0 | 83.8 | 89.8 | 83.5 | — | 81 |
| Coding | ||||||
| SWE-bench Pro | 62.1 | 58.4 | 55.4 | 69.2 | 58.6 | 54.2 |
| DeepSWE | 46.2 | 18 | 8 | 58 | 70 | 10 |
| Terminal-Bench 2.1 (Terminus-2) | 81.0 | 63.5 | 64 | 85 | 84 | 74 |
| FrontierSWE (Dominance) | 74.4 | 30.5 | 29.0 | 75.1 | 72.6 | 39.6 |
| SWE-Marathon | 13.0 | 1.0 | — | 26.0 | 12.0 | 4.0 |
| Agentic | ||||||
| MCP-Atlas (public) | 76.8 | 71.8 | 73.6 | 77.8 | 75.3 | 69.2 |
| Tool-Decathlon | 48.2 | 40.7 | 52.8 | 59.9 | 55.6 | 48.8 |
2. Where it leads, where it trails
- Leads — agentic / long-horizon coding + competition math. GLM-5.2 sits in the top tier on the hardest agentic-SWE sets: FrontierSWE 74.4 (vs Gemini 39.6, DeepSeek 29.0, and its own GLM-5.1 at 30.5), DeepSWE 46.2 (vs Gemini 10, MiniMax 20), SWE-Marathon 13.0 (≥ GPT-5.5's 12). On math it's at or above the closed frontier: AIME 99.2 and IMOAnswerBench 91.0 are the table's best. This is the "agentic engineering" bet paying off.
- Competitive — tight with closed frontier. Terminal-Bench 81–82.7 (Opus 85, GPT-5.5 84), SWE-bench Pro 62.1 (beats GPT-5.5 58.6 / Gemini 54.2; trails Opus 69.2), MCP-Atlas 76.8 (Opus 77.8).
- Trails — broad knowledge / general reasoning. HLE 40.5 (Opus 49.8, Gemini 45), GPQA 91.2 (Gemini 94.3, Opus/GPT-5.5 93.6), Tool-Decathlon 48.2 (Opus 59.9). The open model is frontier-grade where it was designed to be (long-horizon coding) and a step behind on broad knowledge — exactly what the title implies.
3. Comparability gotchas (read the footnotes)
Even a single self-published table is not apples-to-apples — GLM's own footnotes prove it:
- Each benchmark uses a different harness/scaffold. SWE-bench Pro via OpenHands; ProgramBench via Claude-Code 2.1.156; Terminal-Bench reported under two harnesses (Terminus-2 and a Claude-Code run → two separate rows, 81.0 vs 82.7); DeepSWE via mini-swe-agent. The scaffold is doing a lot of the work.
- Context windows vary 256K → 1M across rows (Terminal-Bench 256K; FrontierSWE / PostTrainBench / SWE-Marathon at 1M).
- Judges differ: GPT-5.5 (medium) judges the math sets; Gemini-3.0-Pro judges MCP-Atlas.
- Subsets mix:
*= full-set HLE for the closed models, while GLM reports the text-only subset by default — so the HLE column isn't one metric. - Third-party measured: FrontierSWE by Proximal, PostTrainBench by PostTrainBench, SWE-Marathon by Abundant AI.
So the lesson the /benchmarks page and the eval reports keep making holds even here: the harness is the benchmark. A bare "SWE score" without the scaffold, context window, judge, and subset is not a number you can rank.
4. What it means for an eval / RL-environments founder
1. Open-weight agentic frontier is real. An MIT-licensed model is in the Opus/GPT-5.5/Gemini tier on agentic SWE (FrontierSWE, Terminal-Bench, SWE-bench Pro). The open/closed gap on long-horizon coding has nearly closed; the remaining gap is broad knowledge (HLE/GPQA). 2. The agentic-coding eval stack is fragmenting fast — FrontierSWE, DeepSWE, SWE-Marathon, ProgramBench, PostTrainBench, Terminal-Bench, NL2Repo, MCP-Atlas, Tool-Decathlon — each with its own harness, and several measured by independent third parties. That third-party-eval pattern (Proximal, Abundant AI) is itself the emerging business. 3. The defensible eval product is the vendor-neutral harness that runs these the same way across models — because, as GLM-5.2's own footnotes show, even a lab trying to be transparent can't make its columns comparable.